
Interview with Nate Coraor: CVMFS & Galaxy
Find out about Galaxy's favorite filesystem
This month we interviewed Nate Coraor of the Galaxy Team to learn about what CVMFS is and how it is being used for Galaxy.
Hi Nate, Thanks for doing this blog-terview, Can you tell us a bit about yourself and how you fit into the Galaxy?
I’m the system administrator for usegalaxy.org (aka. Galaxy Main) and most of the rest of the Galaxy Project infrastructure (Jenkins, the Tool Shed, various web servers, DNS, etc.). I came to Galaxy when I joined the Nekrutenko Lab at Penn State in 2006. Beyond system administration, I’ve written a fair amount of the project’s Ansible content, admin documentation, and Galaxy components (mainly the ones that interface with the system in some way).
There is lots of buzz on support channels and presentations lately about CVMFS and Galaxy. Can you tell us a bit about what CVMFS is?
CVMFS (or CernVM-FS) is a filesystem developed at Cern for the purpose of distributing software. It’s a distributed read-only HTTP-based filesystem, meaning that it works with most firewall setups. I originally heard about it thanks to a lightning talk at the 2016 Galaxy Community Conference by David Morais, who was using it at the time to distribute Galaxy to compute clusters.
CVMFS uses a tiered model to distribute data in a scalable and fault tolerant manner. From the canonical Stratum 0 source of the data, multiple full copies are made to geographically disparate Stratum 1 replica servers. An optional level of site-local proxy servers helps to reduce load on Stratum 1 servers. This infrastructure allows clients to mount the filesystem, but only pull in the file attributes and contents that they need. The system is very well load balanced and fault tolerant through the aforementioned geographic distribution and aggressive caching.
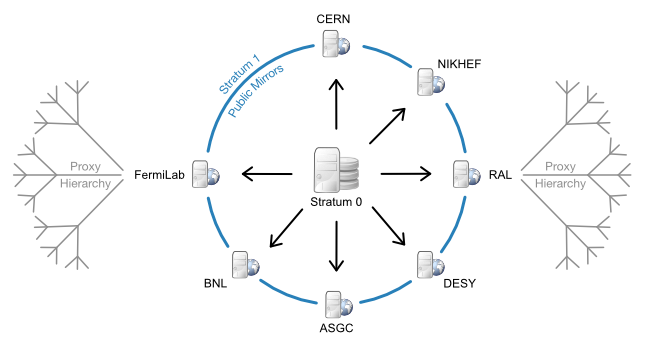 |
| CVMFS tiered architecture example source: https://cvmfs.readthedocs.io/en/stable/cpt-replica.html. |
How is CVMFS being used in Galaxy?
Prior to 2016, Galaxy was contained within a single data center at TACC with access to the same global filesystem. When Jetstream came online, I needed a way to get a copy of Galaxy and its tool dependencies on to the cloud instances we obtained from Jetstream so that we could run Galaxy jobs on them. Although designed for software distribution, I subsequently discovered that CVMFS could also house and distribute the roughly 8 TB of reference data that we host for usegalaxy.org’s tools.
So, in 2016, I set up a small CVMFS deployment for usegalaxy.org, with Stratum 1 servers located here at PSU, in Jetstream at Indiana University, and in Jetstream at TACC. There were a few kinks to work out with automating Galaxy and reference data deployment to CVMFS, but eventually this system came to work very well and very reliably.
What are the implications of adopting CVMFS in Galaxy?
When I first set up CVMFS in 2016, it was for my own purposes, and I hadn’t considered that it would be of use to anyone else. Other Galaxy Team members eventually became aware of my CVMFS deployment and Enis Afgan approached me about using CVMFS to get the same reference data as available on usegalaxy.org in to the Galaxy CloudMan and Genomics Virtual Lab (GVL) cloud images. These images are used by CloudLaunch for anyone to create and scale private Galaxy servers in a wide array of clouds. This had long been a wish, and the small amount of manually curated data previously available to CloudMan instances had always been a pain point for Enis.
It turned out that getting CloudMan to use CVMFS was quite simple: Enis simply added the CVMFS client to the cloud images, pointed it at my Stratum 1 servers, and instructed Galaxy to load data from there - and it worked! Overnight, cloud instances were able to access and use all the same reference data that we’d laboriously curated over 10+ years for usegalaxy.org.
As news of this success got out, others wanted to use the same data. It’s now available in Björn Grüning’s [Galaxy Stable Docker image])https://github.com/bgruening/docker-galaxy-stable), as well as the usegalaxy.eu and usegalaxy.org.au public servers, among others. My usegalaxy.* admin counterparts, Helena Rasche and Simon Gladman, have even deployed their own Stratum 1 replicas in Freiburg and Melbourne, respectively, and the EU’s Joint Research Centre hosts one in Ispra, Italy.
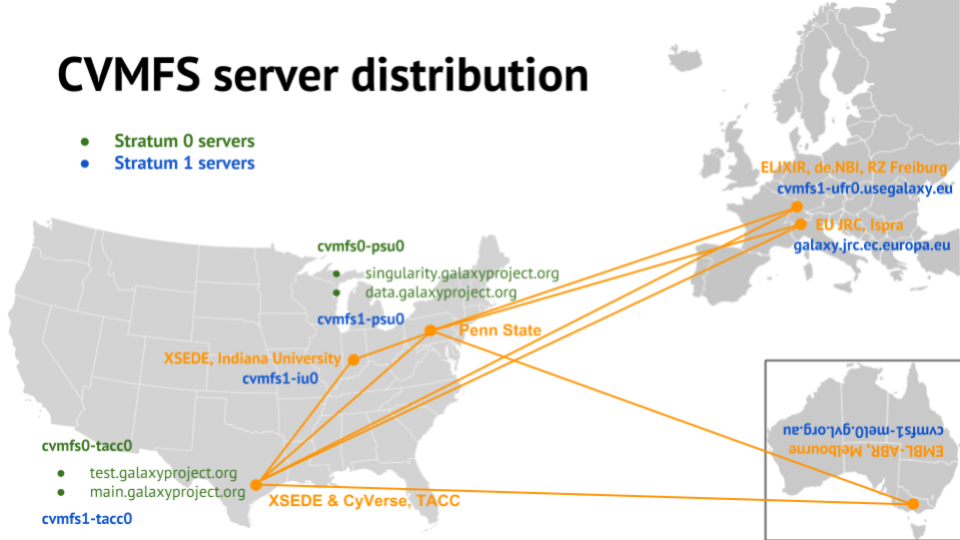 |
| Galaxy Project CVMFS infrastructure, February 2019. |
How can current system admins of Galaxy implement CVMFS reference management for their Galaxy instance?
We’ve created a fair amount of documentation and materials around it. Instructions can be found in the Hub, there is a tutorial in the Galaxy Training Network, and an Ansible role for setting up not only CVMFS clients, but your own Stratum 1 or local cache. Finally, you can browse the data at datacache.galaxyproject.org, which is also available via rsync. If you have any trouble, there is an admins channel on the galaxyproject Gitter full of people who can help you out.
What are the next steps in the evolution of CVMFS reference management of Galaxy?
Helena and Simon recently visited Penn State to teach at the 2019 Galaxy Admin Training, and stayed a week after to collaborate on solving our usegalaxy.* problems. One result of that work is the Intergalactic Data Commission (IDC), which seeks to do for reference data what the IUC did for tools. We’ll hopefully have more to say about that by the GCC.
Before we let you go, can you show us the infamous schematic of how Galaxy works?